가끔 PDF나 이미지 파일의 글씨가 필요한데 복사가 안 되어서 일일히 타이핑하거나
표 내용을 복사하고 싶은데 단순 복사로는 표 모양을 살리지 못하는 문제가 가끔 있다.
그럴 때 휴대폰에서는 OCR이 되는데...라며 슬퍼하지만
그렇다고 모든 파일을 휴대폰으로 옮기고 → 글자 인식하고 → 다시 컴퓨터로 옮겨서 → 문서 작성에 활용
...하는 것은 좀 복잡하고 문제가 있지 않는가?
그래서 컴퓨터에서 github에 있는 프로그램으로 OCR 기술을 활용해보려고 한다.
프로그램 설치 몇 개만 하고 명령 프롬프트(혹은 윈도우 PowerShell 혹은 리눅스 Bash)에 몇 줄만 치면 금방 결과가 나오니
코딩이 나온다고 겁나하지 말고 잘 따라해보자.
OCR이란? Optical Character Recognition의 약자로 이미지 내의 텍스트를 인식하여 텍스트 데이터로 변환하는 기술이다.
Github의 VikParuchuri라는 개발자님께서 제작하고 배포한 거라서 아래 링크에 가면 설명이 잘 나와있는데
https://github.com/VikParuchuri/surya/
https://github.com/VikParuchuri/tabled
코딩이 두렵고 영어가 어려운 분들을 위해 설명하는 것이니
정확한 정보를 위해서는 해당 링크를 참고하자.
1. Python과 Pytorch를 설치한다.
단, 배포판을 주의해야한다.
오늘 날짜(2024년 12월 4일) 기준, Pytorch는 Python 3.13 버전에서 설치가 안 된다.
따라서 Python을 3.12 버전으로 설치한 뒤, Pytorch를 다운받아야 한다.
① Python 3.12 버전 (https://www.python.org/downloads/release/python-3120/)
위 링크에 들어가서 스크롤을 쭉쭉 내리면 Files 항목이 있다.
본인의 컴퓨터에 맞는 파일을 다운받아서 연 다음에 설치하면 된다.
설치 시 처음 나오는 창의 하단에 나오는 'Add python.exe to Path' 항목에 꼭 체크를 해 준다.


② Pytorch 설치 (https://pytorch.org/get-started/locally/)
설치 전, 위 링크에 들어가서 살짝 스크롤을 내려 아래와 같은 화면이 나오게 한다.
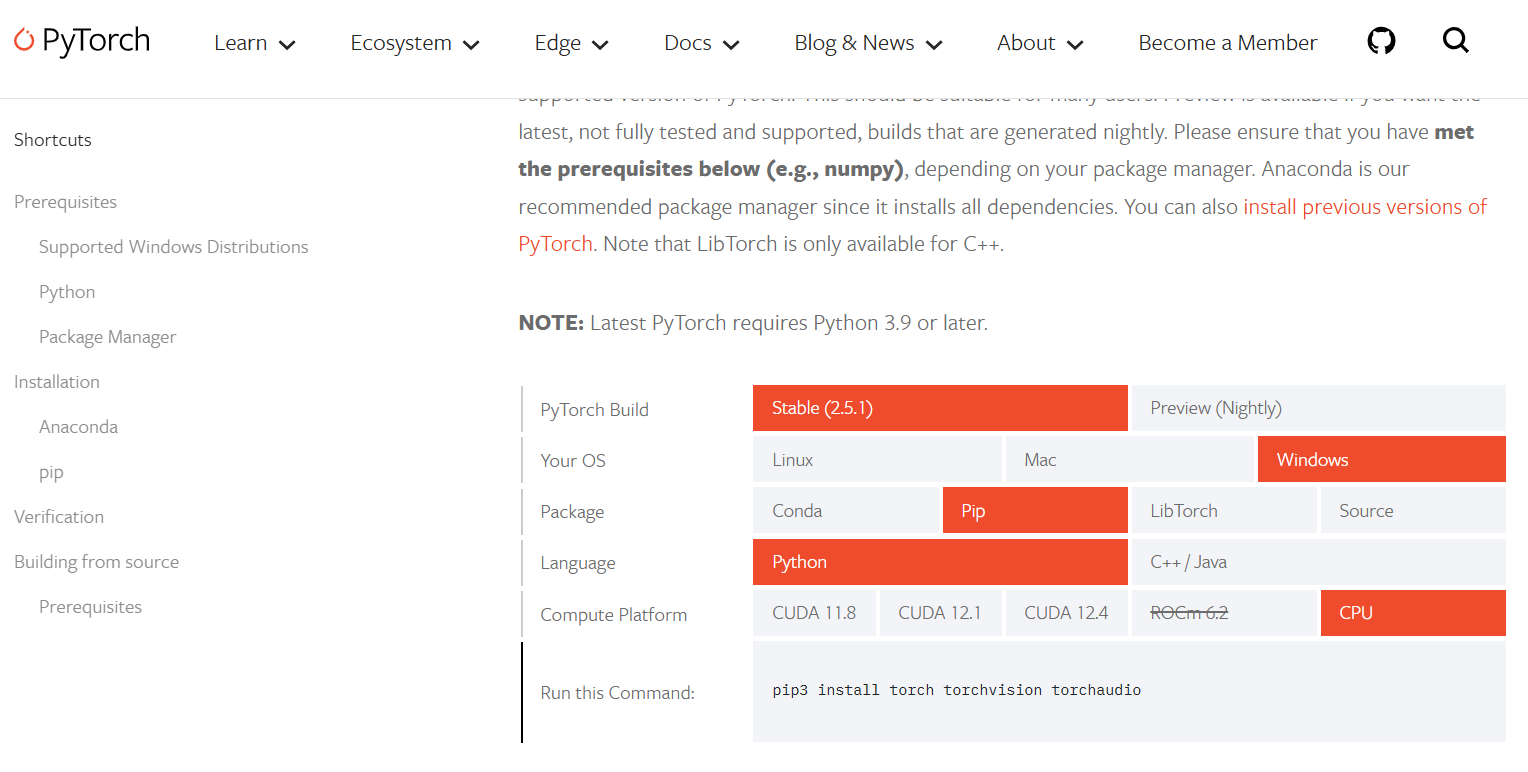
여기서 자기 컴퓨터가 무엇을 쓰는지 주황색으로 선택해주면, Pytorch를 깔 수 있는 명령어가 나온다.
즉, 나 같은 경우는 stable 버전으로 받을거고, 윈도우에서 깔고 싶고,
파이썬을 깔아두었고, 그냥 pip를 쓸거고(Pip는 파이썬에 딸려와서 같이 깔리는 패키지이다)
CUDA는 사용이 불가하기 때문에 CPU를 눌렀다.
그러면 'pip3 install torch torchvision torchaudio'라는 명령어가 제공된다.
사람마다 컴퓨터 환경이 다르므로 선택한 것에 따라 명령어가 조금씩 다르다.
pip3 install torch torchvision torchaudio이제 명령 프롬프트를 켜서 저 명령어를 입력하고 엔터를 누른다.

그러면 성공적으로 설치된다!
참고로 파이썬 버전이 최신버전이 아니라 [notice] A new release of pip is available이라는 문구가 뜨는데
잘못 업데이트 하는 순간 Pytorch가 안 먹을 수도 있으니
웬만하면 업데이트하지 말자.
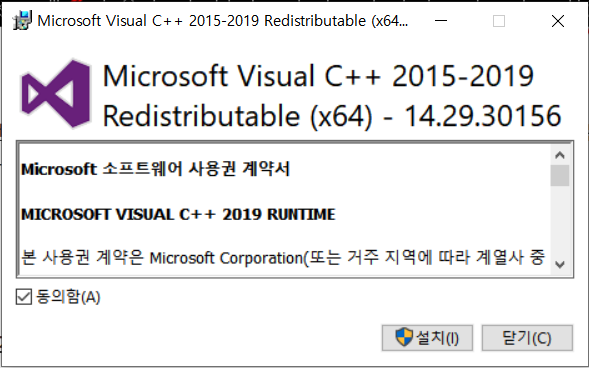
(추가) ③ Microsoft Visual C++ 2015-2019 Redistributable (x64) 설치
내 컴퓨터는 7년간 수많은 코딩시도로 이미 설치가 되어있었는데
설치가 안 되어있는 새 컴퓨터의 경우에는 설치를 해 주어야 작동한다.
https://aka.ms/vs/16/release/vc_redist.x64.exe 에 들어가면 설치프로그램이 다운로드 되니
클릭해서 설치해주면 된다.
2. surya-ocr, streamlit를 설치한다.
아래 코드를 전부 다 명령 프롬프트에 입력하면 된다.
pip install surya-ocr
pip install tabled-pdf
pip install streamlit이해한 바에 따르면, surya-ocr이 글씨를 인식하는 기능이고,
tabled-pdf는 pdf에 있는 표를 인식하는 기능이고,
streamlit는 CLI 환경에 익숙하지 않은 분들을 위해 GUI 환경으로 이렇게 인식했어요~를 보여주는 기능인 것이다.
CLI: 텍스트 기반 인터페이스. 명령 프롬프트가 대표적이다.
GUI: 그래픽 기반 인터페이스. 클릭으로 명령을 시행할 수 있는 대부분의 컴퓨터와 휴대폰이 적용중이다.
3. 사용한다.
① 글자인식이 필요할 때
surya_ocr DATA_PATH여기서 DATA_PATH는 C:/Users/user/.... 뭐 이렇게 되는 것을 뜻한다.
예를 들어보자.
다운로드 폴더에 word.pdf라는 파일을 하나 넣어두었다.
'내 PC > Windows (C:) > 사용자 > a > 다운로드'라고 적힌 부분을 더블클릭하면 해당 폴더의 경로가 뜬다.
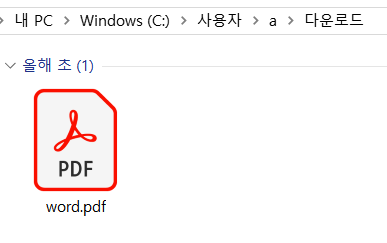
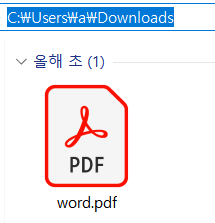
그러면 저 word.pdf의 파일의 path는 'C:\Users\a\Downloads\word.pdf'인 것이다.
(꼭 파일 확장자명까지 써줘야한다!)
참고로 \ 기호나 ₩기호나 키보드에서는 똑같다.
한국어에서는 원화 기호가 되지만 외국어에서는 백슬래시가 되는 듯?
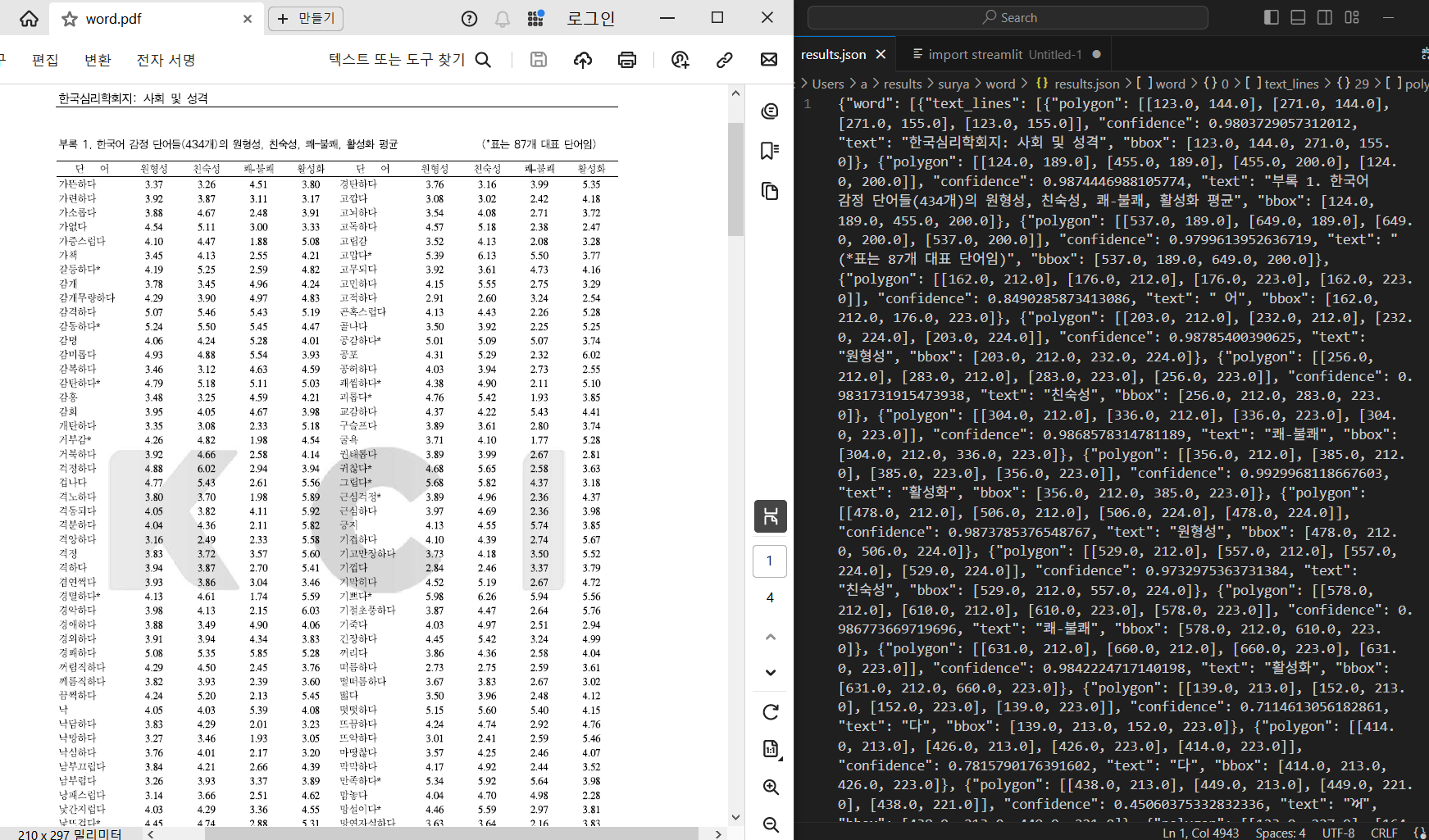
그래서 surya_ocr C:\Users\a\Downloads\word.pdf 라고 명령프롬프트에 입력하면
컴퓨터 사양마다 속도가 다르겠지만 아래와 같이 상황을 알려주면서 열심히 텍스트를 인지해준다.
....컴퓨터는 좋은 거 사자!! (속도 매우 느려 슬픈 1인)
폴더명이나 파일명에 띄어쓰기가 있으면 에러가 나므로 띄어쓰기는 없애자. (사람들이_자꾸_언더바를_붙이는_이유)
또한, 나만 그런지 모르겠는데 한국어로 되어있어도 에러가 나서 영어 폴더명과 파일명으로 다 바꿔준 다음 진행했다.

결과가 results\surya\word에 저장되었다고 뜨는데
현재 명령프롬프트에 있는 디렉토리가 C:\Users\a이므로 (꺽쇠[>] 좌측에 적힌 곳이 디렉토리이다)
그 하위폴더로 생성된 것을 볼 수 있다.

디렉토리를 바꾸고 싶으면 cd명령어를 써서 바꿔도 되고 (cd DIRECTORY_PATH 형식으로 쓰면 된다)
아니면 surya의 세부 기능 중 하나인 --results_dir를 써도 된다.
...표는 아래 설명할 tabled 기능을 쓰자...ㅋㅋㅋㅋㅋ
json 파일이 안 열려요: 반대쪽 클릭해서 '연결 프로그램 > 메모장'하면 열린다. 아니면 Visual Studio Code 같은 프로그램을 깔아도 되고?
세부적인 기능 기능 (PDF의 일부 페이지만, 저장 위치 구체적으로 지정) 등은
내가 다 설명하기엔 힘드니...
github의 원본을 확인해보자! (https://github.com/VikParuchuri/surya/ )
작대기 달린 명령어를 줄줄히 입력 후 엔터를 치면 된다.
예를 들어, surya-ocr --langs ko C:\Users\a\... --results_dir C:\Users\a\... 뭐 이런 식으로...
② 인식이 잘 되었나 궁금할 때
surya_gui라고 명령프롬프트에 입력하면
본인의 컴퓨터를 서버로 하는 인터넷 창 같은 것이 하나 생길 것이다.
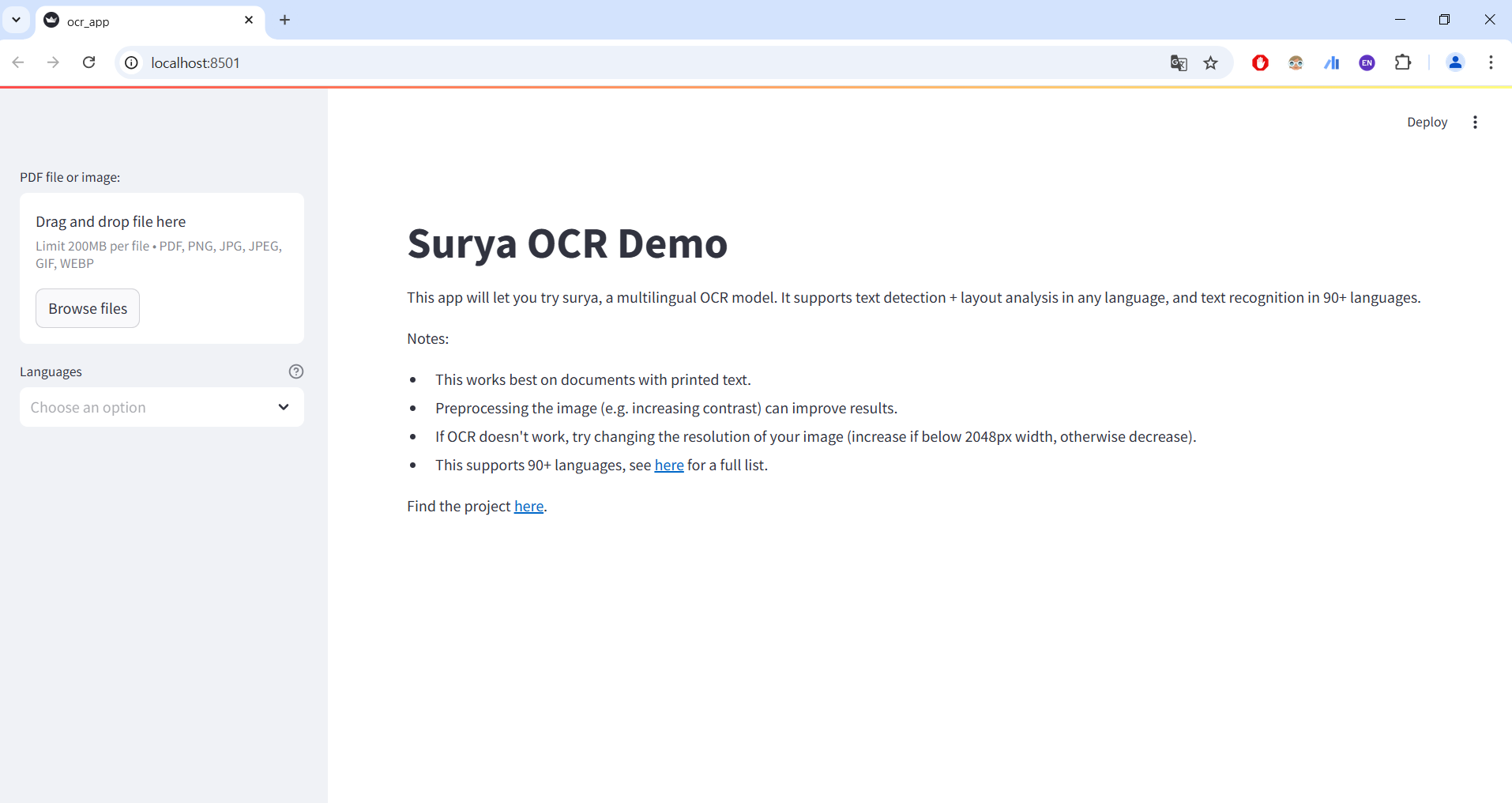
다 로딩이 되면 좌측의 Browse files 버튼을 클릭해 읽고 싶은 파일을 입력할 수 있다.
파일이 입력되면 새로운 버튼들이 생기는데, 원하는 기능을 클릭해보면
아래와 같이 무엇이 인식되었는지 빨간색으로 나타난다.

③ 표를 인식하고 싶다면
tabled DATA_PATH OUTPUT_FOLDER --format csv기본적으로 tabled는 원하는 파일의 경로, 저장될 공간의 폴더 경로를 써야 한다.
나는 tabled C:\Users\a\Downloads\word.pdf C:\Users\a\Downloads --format csv 라고 쳤다.

그러면 해당 경로에 파일명으로 된 폴더가 생성되면서
해당 파일에 있는 모든 표가 png파일과 csv파일로 저장이 된다!


역시 세부 기능이 필요하다면 github 원문을 참고하자.
https://github.com/VikParuchuri/tabled
그러면 다들 기술의 발전을 적극적으로 활용해서 시간 소모가 큰 노가다 작업이 감소되었음 좋겠다.
그리고... 난 내년에 컴퓨터를 바꾸는 것을 적극적으로 고려해봐야징...흑흑
아직 7년밖에 안 썼는데 7년 전에는 AI와 코딩이 이렇게까지 발달할 줄 몰라서
당시의 나에게 아주 적당한 사양으로 샀는데 한계가 느껴진다.
점점 기술이 발달하면 컴퓨터 바꾸는 주기가 빨라지려나...